Intro
- 不需要把所有東西放進dRAM : 不是整支執行檔都會用到
- Partial Loading
- Programmer不需要再考慮空間問題
- 降低每隻程式使用的空間 -> 更多程式同時執行
- 降低Swapping的成本
- Virtual address space
- address從0到空間終點
- Physical memory -> page frames
- MMU自動做位址轉換
- VM空間遠大於physical memory
- 定址空間中允許hole的存在 : 支援動態分配(heap, stack)
Demand paging
- Start
- 不會載入所有page
- 把所有page mark unloded
- Page fault
- 執行時access到還沒載入的page
- 這時才把對應的page載入
- Page load
- 前面handle完之後繼續執行, 就像那個page一直存在
- Page replacement
- swap到disk
- Swap算法
- FIFO
- LRU : 使用過去經驗, Counter / Stack
- Second chance : FIFO + refernce bit (ref==0 才swap out)
- Enhanced second chance : 再加上dirty bit, 優先級為 $dirty < reference$
- Optimal : 預測接下來最久用不到的, 使用LRU近似
Copy-on-write
- 每個process的shared memory都是同一份
- 做寫入時才會做複製
- CoW ->
fork(), no CoW ->vfork() - Shared memory must zero out -> C裡面的global variable初始都是0 (BSS)
Page replacement algorithm
FIFO
LRU : overhead過大(counter / stack)
- 優先級(ref, dirty) :
- (0, 0)
- (0, 1)
- (1, 0)
- (1, 1)
LFU : 最少reference
OPT : 預測未來, 做不到但是可以預測upper bound
Fixed allocation : 為每個CPU分配固定數量的page
Reclaiming page : 當free page低於某數量 -> 開始進行swap out, 不要等0再開始做
Thrashing
- CPU花太多時間在replacement, 而不是真正的work
原因
- Working set 過大
- 程式的執行模式缺乏局部性
- 不合理的多工數量
解決
- 縮減working set
- 調整page size
Working set
- 指定時間內活躍的page set, 被認定為正常執行所需
- 令 $W(t, \delta)$ 以及 Process $p$: $$ W(t, \Delta) = { p | ( p \quad is \quad accessed \quad in \quad past \quad \Delta ) } $$
Kernel memory allocation
Overview
- 3-level structure
- Node :
struct pgdata_list - Zone :
struct zone,ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM - Page :
struct page
Page structure
flags, 8 bytes , Page flagsunion, 40 bytes, 管理功能metadataunion, 4 bytes,memmap_mapcount_refcount, 使用次數- others, 看kernel config
Zone structure
- Free area : 0 ~ 10 (每個都是linked list)
- 10 consists $2^{10}$ pages for each list entry (
free_area[0]: $2^0=1$)
- 10 consists $2^{10}$ pages for each list entry (
Node structure
- 每個memory controller為一個node
- 對於NUMA而言同一個CPU對應的controller是local memory
Buddy system
- 在Zone裡面的
free_area[order], order為11 - 每個下標對應的Page size : $2^{order}$
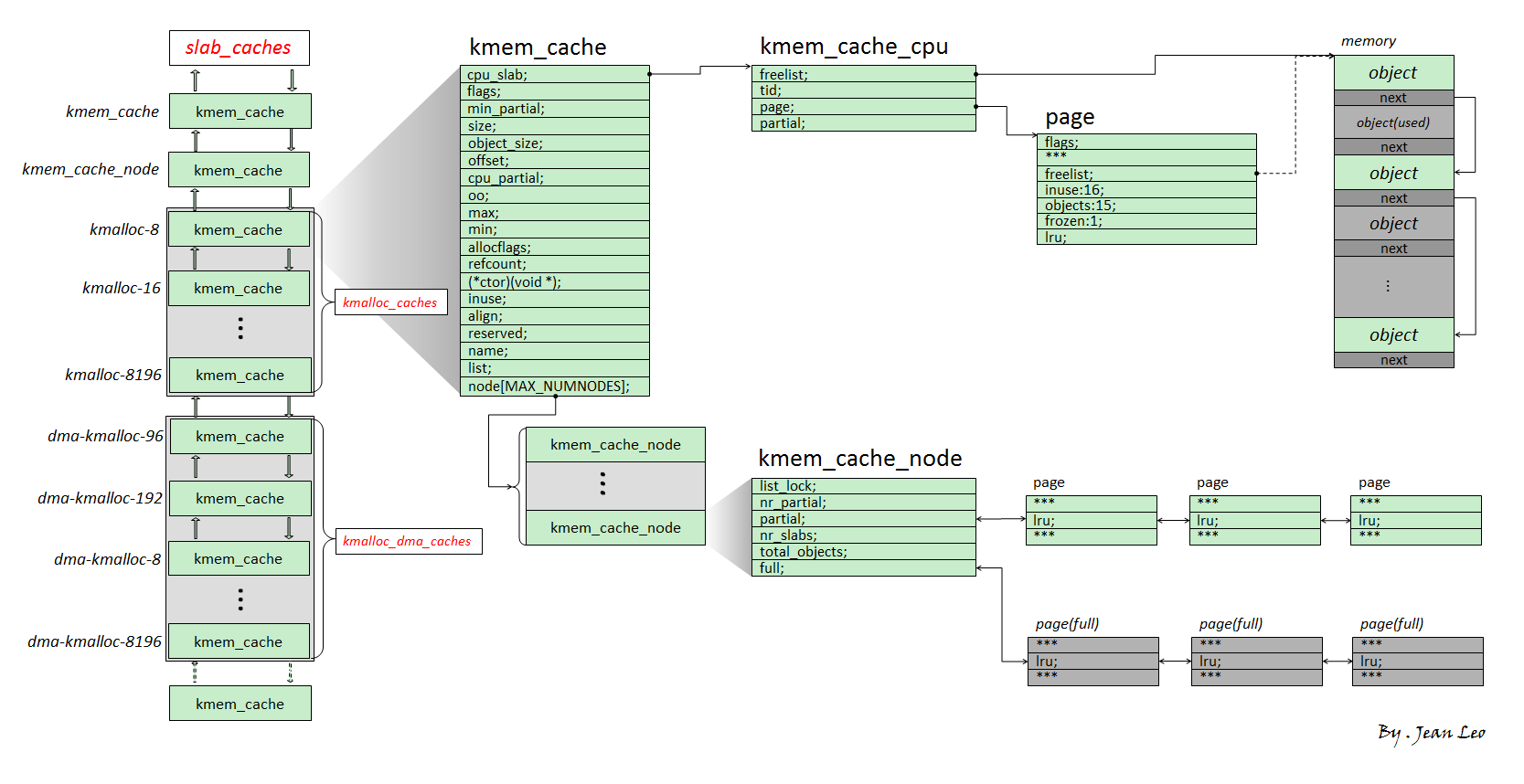
Slub overview (現在的slab allocator)
kmem_cache: allocator, 組成一個doubly-linked list, 用來分配指定size, 每個entry都擁有:kmem_cache_cpu: Per-CPU variable, 用來表示正在使用的slub -> 從kmem_cache_cpu取object不需要lockkmem_cache_node: 存放兩個slub list :- partial : 該slub有free object
- full : 沒有
Slub workflow
Allocate
kmem_cache_cpu上面拿object- 從
current->partial拿 - 從buddy system請求過來, 分成object給
kmem_cache_cpu, 取free object
Free
- 從
kmem_cache_cpu-> 插入freelist (insert at head) - 從
kmem_cache_node->partial-> 插入freelist (insert at head) - free一個full slub -> freelist head node, 把這個slab放到partial
full view :